Web上の表(tableタグでフォーマットされたデータ)を読み込んで利用する方法
久々の投稿の阿形です。
久々なのに、またもや小ネタ。
Webにはいろんなデータがありますが、それらはtableタグでフォーマットされていることが多いと思います。
今回はそんなデータを読み込む方法について書いてみようと思います。
なんでこんなネタになったかというと、仕事で「AWSのCloudWatchのメトリクスを表にまとめてほしい」と言われたからです。
そんなんURL貼っとけばええやん!という声も聞こえてきそうですが、まあそれはそれ。
提案資料とかにまとめるのに必要だったりするんですよこれが。
こういうのが日本の生産性低下の原因だーとかTwitterでいじられそうですが、ちょっとでも楽するためにその方法をまとめておこうかと思いました。
今回ご紹介する方法は以下の3通りです。
- Excelを使用する方法
- Google Spreadsheetを使用する方法
- Pythonを使用する方法
1.Excelを使用する方法
一番需要が多そうな方法なんですが、結果としては一番残念な感じです。
以下の説明ではOffice 365でダウンロードしたMac版Excel(16.13.1)を使用しています。
1. 前準備として読み込むWebページをHTMLファイルとしてダウンロードしておきます。
2. Excelを起動し、新しいBookを開きます。
3. 「データ」タブをクリック。

4. 左上の「HTMLから」をクリックします。HTMLファイルの読み込みページが開きます。読み込むHTMLファイルを選択して「開く」をクリックします。

5. 読み込んだWebページが表示されます。
以上です。
とまあ、簡単に読み込めはするんですが、なんとも残念なのがテーブルの解析方法。
テーブルのセルとExcelのセルが対応してくれれば扱いやすいのに、余計なお世話で<p>タグを個別のセルに分割してくれちゃってます。
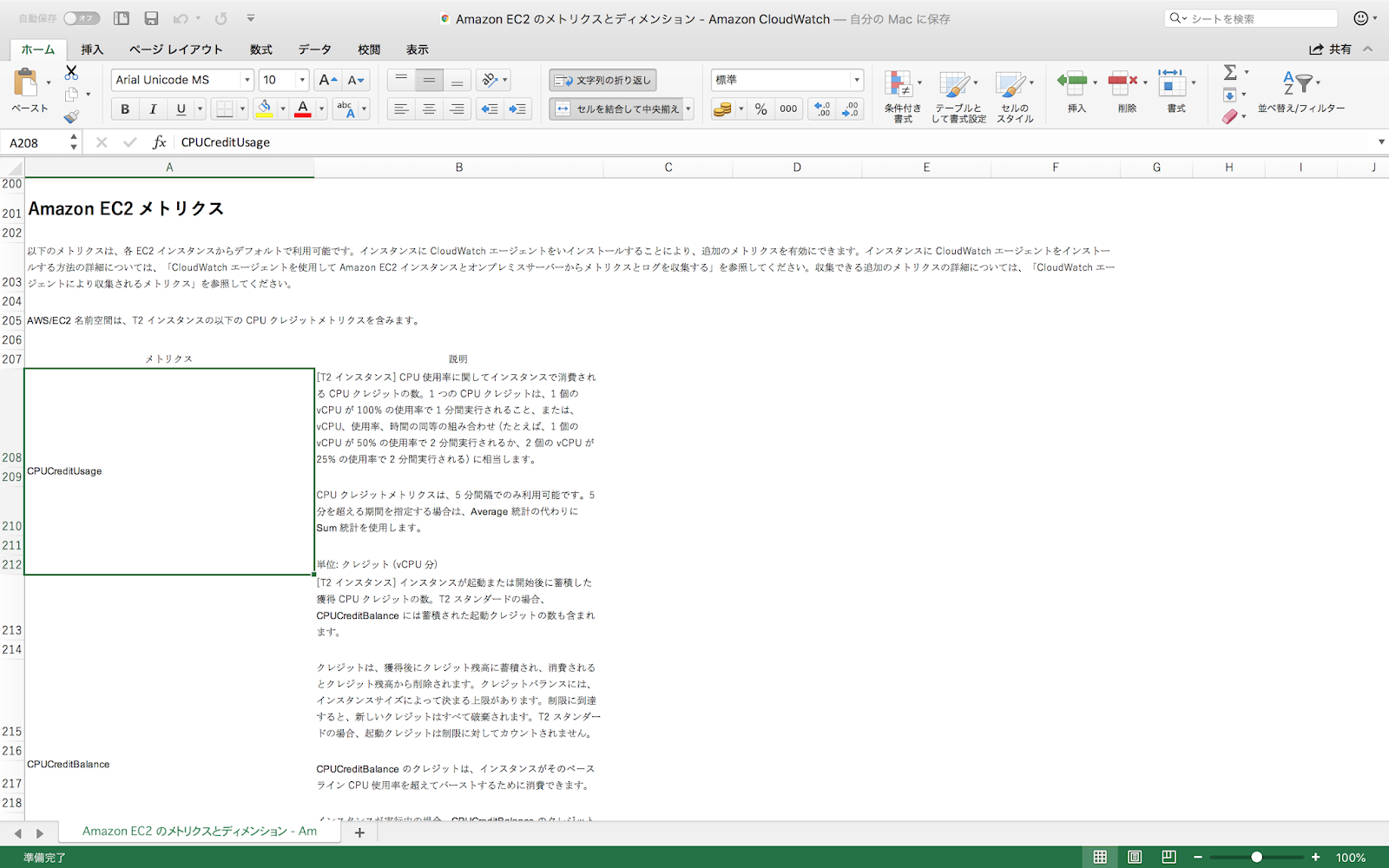
※2カラム目の文章が<p></p>で段落を区切っているので、それぞれ別のセルに分割されている。
なお、Excelにはこれとは別に「取得と変換」(2016以前はPowerQuery)なるものを使ってやる方法もあるようですが、どうもMac版ではWindows版と違うようでよくわかりませんでした。
Microsoftの頻繁にUIとか機能変えたがるのはなんとかならないもんですかね…。
2. Google Spreadsheetを使用する方法
これは超簡単です。
IMPORTHTML関数を使用する方法です。
1. ブラウザでGoogle Spreadsheetを開きます。

2. 取得したいテーブルがWebページの何番目にあるかを確認します。やり直しはいくらでもできるので、このあとのステップで修正を繰り返すのもありだと思います。
3. テーブルのデータを挿入したいセルに以下の内容を入力します。
=IMPORTHTML("URL","クエリ",指数)
URLには取得したいWebページのURLを指定します。
ここではhttps://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/ec2-metricscollected.html
を指定します。
クエリは取得する対象のタグによりtable、またはlistを指定します。今回はtableタグの中身を取りたいので、tableを指定します。
指数はHTMLの中でクエリに指定したタグの何番目に出てきたものを取得するかを指定します。
今回は3番めに出てきているtableだったので、3を指定します。
これらを反映すると、こんな感じの指定になります。
=IMPORTHTML("https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/ec2-metricscollected.html","table",3)

4. 入力してエンターを押すと、しばらくLoadingと表示されます。

5. ロードが完了すると、指定したURLの指定した順番のテーブルが表示されます。
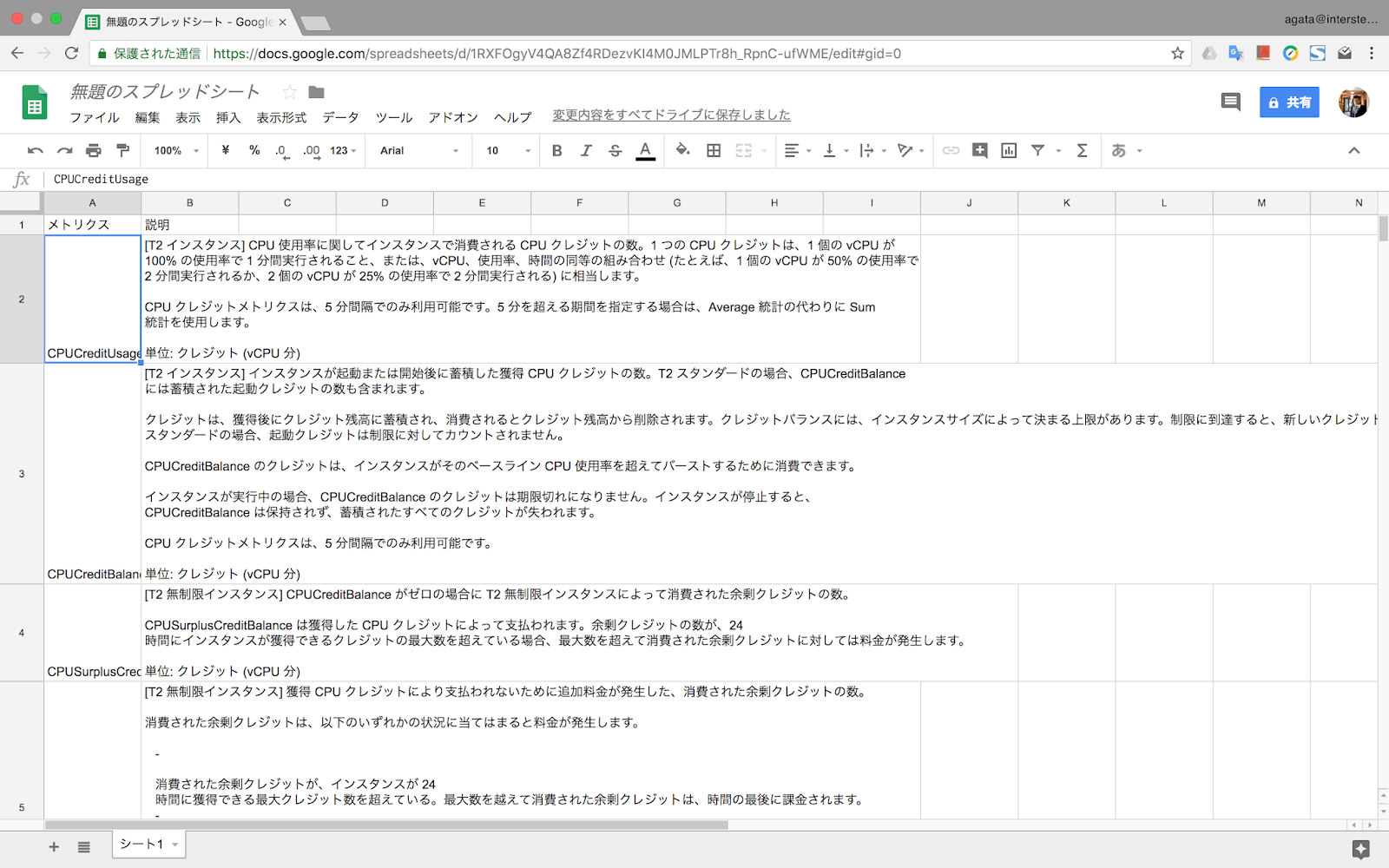
以上です。
Google SpreadsheetはIMPORTHTML関数さえ知っていれば、とても簡単に使える上、Excelみたいに変な分割をされないので超おすすめ。
単純なテーブルならこれで十分だと思います。
というかExcel要らねえ…。
ExcelもBIツールとして機能追加しているようですが、個人的には軽く使うならGoogle Spreadsheetでテーブル読み込んで、Google Datastudioでビジュアライズするというのが結構オススメです。全部無料だし。
3. Pythonを使用する方法
えー今回の自分の目的としては、上記のGoogle Spreadsheetで十分だったので、そこまでにしても良かったんですが、まあ何かのためにとPythonでやる方法も簡単に紹介しておきます。
Pythonを使用する場合、プログラム言語なのでいろいろなやり方が考えられますが、おそらく最も簡単なのはpandasを使用する方法かなと思います。
pandasはPythonでのデータ解析用のライブラリで、HTMLの解析も行うことができます。
実際のサンプルコードはこんな感じ。
import pandas
url = 'https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/ec2-metricscollected.html'
dataframes = pandas.read_html(url)
dataframes[3].to_csv('data.csv',encoding="shift-jis")
たったこれだけで、指定したURLからHTMLファイルを取得し、その中のテーブルをCSVに書き出すことができます。(ここではExcelで読み込む前提で、Shift-JISで出力しています。)
詳しい使い方まで突っ込みだすとキリがないぐらい機能豊富なので、もっと使い倒したい方はpandasのドキュメントを参照してください。
データを読み込んで自動処理するとか、複雑なデータ解析をやったりする場合はPythonで読み込めると便利ですよねー。
まとめ
という感じで、個人的おすすめは
- 簡単に使いたいときはGoogle SpreadsheetのIMPORTHTML関数
- 複雑なデータ解析をやりたいときはPython+pandas
-
 NSDとUnboundでのDNS権威サーバーとキャッシュサーバー構築
NSDとUnboundでのDNS権威サーバーとキャッシュサーバー構築
-
WordPressのサーバー引っ越しで色々エラーになった件
-
Linux、Mac、Windowsの各端末間でネットワーク性能を計測する(iperf/ntttcp)
-
AWS IAM Identity CenterでViewOnlyAccessだけだとHealth Dashboardを見られないのに対応する
-
Amazon S3 Glacier Instant Retrieval 128KB問題。S3よりどれぐらいコスト削減できるか試してみた
-
Amazon EC2でAmazon Linux 2023を選んだら、nginxのインストールでハマった件
- Stable DiffusionをM1 macのローカルで動かしてみた
-
![]() AWS SSOの有効化と基本設定
AWS SSOの有効化と基本設定
-
MacにHomebrewを用いてTexをインストールする
-
VR180の動画を2D動画にffmpegで変換する
-
![]() Amazon S3でイベント通知をAmazon SNSに送信するよう設定しようとしたら “Unable to validate the following destination configurations” というエラーが出る場合の対処
Amazon S3でイベント通知をAmazon SNSに送信するよう設定しようとしたら “Unable to validate the following destination configurations” というエラーが出る場合の対処
-
![AWS SSO]() AWS Single Sign-OnでCLIを使う
AWS Single Sign-OnでCLIを使う
-
![]() Amazon Elastic Load Balancingで固定IPアドレスを使用する – NLBでの設定
Amazon Elastic Load Balancingで固定IPアドレスを使用する – NLBでの設定
-
![]() Amazon Elastic Load Balancingで固定IPアドレスを使用する – Global Acceleratorでの設定
Amazon Elastic Load Balancingで固定IPアドレスを使用する – Global Acceleratorでの設定
-
![]() Amazon Elastic Load Balancingで固定IPアドレスを使用する
Amazon Elastic Load Balancingで固定IPアドレスを使用する
-
MacにHomebrewでDockerをインストールする
-
![]() Organizationに依存せず、複数アカウントのCloudTrailログを監査用アカウントに集約する方法
Organizationに依存せず、複数アカウントのCloudTrailログを監査用アカウントに集約する方法
-
![]() Macのホームフォルダを外付けディスクに移動する
Macのホームフォルダを外付けディスクに移動する
-
Raspberry Piで取得したセンサーデータをBigQueryに投げてGoogle データポータルでグラフ化してみる
-
Sphinx + blockdiag + Netlifyで日本語フォントを使う